네이버 블로그를 통해 cv::Mat 클래스를 선언하고 생성하는 기본적인 방법에 대해 알아봤어요.
이번에는 cv::Mat 의 원소 접근 방법과 사용할 수 있는 멤버 변수와 함수에 대해 좀 더 자세히 살펴봐요.
cv::Mat 멤버 변수

cv::Mat src;
를 기준으로 멤버 변수와 함수를 설명할께요. 영상 사이즈는 640x480, 1ch/3ch, 8bit/16bit 기준으로 계산해봤어요.
|
표현식
|
설명
|
8bit 1ch
|
8bit 3ch
|
16bit 1ch
|
16bit 3ch
|
|
src.cols
|
열의 개수
|
640
|
640
|
640
|
640
|
|
src.rows
|
행의 개수
|
480
|
480
|
480
|
480
|
|
src.dims
|
행렬의 차원
|
2
|
2
|
2
|
2
|
|
src.data
|
데이터 포인터
|
시작 주소 값
|
시작 주소 값
|
시작 주소 값
|
시작 주소 값
|
|
src.step
|
한 행의 바이트 수
|
640 x 1 x 1
|
640 x 1 x 3
|
640 x 2 x 1
|
640 x 2 x 3
|
|
src.step1( )
|
step/elemSize1( )
|
640
|
640 x 3
|
640
|
640 x 3
|
|
src.total( )
|
전체 요소 개수
|
640 x 480
|
640 x 480
|
640 x 480
|
640 x 480
|
|
src.elemSize( )
|
한 요소의 바이트 크기
|
1
|
3
|
2
|
6
|
|
src.elemSize1( )
|
한 요소의 바이트 크기 (채널 무시)
|
1
|
1
|
2
|
2
|
|
src.type( )
|
데이터 타입
(자료형+채널) |
CV_8UC1
|
CV_8UC3
|
CV_16UC1
|
CV_16UC3
|
OpenCV 에서는 3채널(컬러) 영상을 보통 BGR 순으로 배열을 해요.
cv::Mat 원소 접근 방법
cv::Mat 원소에 직접 접근하는 방법은 크게 3가지가 있어요.
사실 더 많이 있는데, 3가지만 알면 충분합니다.
일단 CV_8UC1에 대해 설명을 드릴께요.
1. at 사용
유효성 검사를 진행하여 안정적이지만 느리다고 알려져있는 방법이에요.
직관적이어서 교육 할 때는 가끔 사용되지만
속도 때문에 실무에서는 많이 사용이 되지는 않습니다.

for(int y = 0; y < src.rows; ++y) {
for(int x = 0; x < src.cols; ++x) {
uchar val = src.at<uchar>(y, x);
src.at<uchar>(y, x) = val + 1;
}
}여기에서 인덱스가 (row, col) 순서라는 것에 주의하세요. 아래와 같이요.

2. ptr 사용
ptr을 사용하여 첫번째 row에 해당하는 첫번째 데이터 주소값을 얻을 수 있습니다.
그래서 주소값에 x 위치만큼 떨어진 곳의 값을 가져오거나 쓰기 쉽죠. 하지만 유효성 검사를 하지는 않습니다.

for (int y = 0; y < src.rows; ++y) {
uchar* pSrc = src.ptr<uchar>(y);
for(int x = 0; x < src.cols; ++x) {
uchar val = pSrc[x];
pSrc[x] = val + 1;
}
} 3. data 사용
data를 사용하면 영상의 첫 위치인 (0, 0) 의 주소값을 얻을 수 있습니다.


data를 사용하면 ptr과 달리 모든 값이 일렬로 늘어져 있다고 생각해야 합니다.
즉, (src.cols * y + x)와 같이 원소에 접근해야 합니다.
uchar* pSrc = src.data;
for (int y = 0; y < src.rows; ++y) {
for (int x = 0; x < src.cols; ++x) {
uchar val = pSrc[src.cols * y + x];
pSrc[src.cols * y + x] = val + 1;
}
}그럼 이번에는 각 원소 접근법 별로 속도 측정을 직접 해 보겠습니다. 그리고 빠른 접근 방법도 함께 알아볼께요.
실험 개요
- Test 환경:
CPU: i7-1165G7, 2.80 GHz
RAM : 16GB
OpenCV 버전: 4.6.0
- 비교군:
at, ptr, ptr 개선, data, parallel_for 이용 ptr, parallel_for 이용 ptr 개선, parallel_for 이용 data
- 측정 대상 영상:
512x512 gray 영상, 1024x1024 gray 영상, 2048x2048 gray 영상, 4096x4096 gray 영상, 8192x8192 gray 영상, 16384x16384 gray 영상
- 비교 방법:
각 size 영상별 30회씩(통계적으로 의미가 있으려면 최소 30회 이상 반복 측정 필요) 전체 원소에 순회하면서 접근하여 데이터를 읽어보고 데이터에 +1을 한 후 다시 원소에 적는 간단한 연산 추가하여 속도 비교
- 기타:
영상은 512x512 lena 원본 영상을 가로x2, 세로x2씩 tile처럼 붙여가며 생성하여 큰 사이즈 영상 생성함
영상 사이즈 별로 속도 비교 측정 (release 모드에서 측정함)
생성된 영상 샘플은 아래와 같음

비교군 소스는 아래와 같습니다.
// 1. at 사용
for (int y = 0; y < src.rows; ++y) {
for (int x = 0; x < src.cols; ++x) {
uchar val = src.at<uchar>(y, x);
src.at<uchar>(y, x) = val + 1;
}
}
// 2. ptr 사용
for (int y = 0; y < src.rows; ++y) {
uchar* pSrc = src.ptr<uchar>(y);
for (int x = 0; x < src.cols; ++x) {
uchar val = pSrc[x];
pSrc[x] = val + 1;
}
}
// 2.1. ptr 속도 최적화
for (int y = 0; y < src.rows; ++y) {
uchar* pSrc = src.ptr<uchar>(y);
uchar* pSrc_end = pSrc + src.cols;
for (; pSrc < pSrc_end;) {
uchar val = *pSrc;
*pSrc++ = val + 1;
}
}
// 3. data 사용
{
uchar* pSrc = src.data;
for (int y = 0; y < src.rows; ++y) {
for (int x = 0; x < src.cols; ++x) {
uchar val = pSrc[src.cols * y + x];
pSrc[src.cols * y + x] = val + 1;
}
}
}
// 4. parallel_for 사용_ptr
Concurrency::parallel_for(int(0), src.rows, [&](int y)
{
uchar* pSrc = src.ptr<uchar>(y);
for (int x = 0; x < src.cols; ++x) {
uchar val = pSrc[x];
pSrc[x] = val + 1;
}
});
// 4.1 parallel_for 사용_ptr 속도 최적화
Concurrency::parallel_for(int(0), src.rows, [&](int y)
{
uchar* pSrc = src.ptr<uchar>(y);
uchar* pSrc_end = pSrc + src.cols;
for (; pSrc < pSrc_end;) {
uchar val = *pSrc;
*pSrc++ = val + 1;
}
});
// 5. parallel_for 사용_data
{
uchar* pSrc = src.data;
Concurrency::parallel_for(int(0), src.rows, [&](int y)
{
for (int x = 0; x < src.cols; ++x) {
uchar val = pSrc[src.cols * y + x];
pSrc[src.cols * y + x] = val + 1;
}
});속도 측정은 ms 단위로, chrono 기반으로 측정하였어요
실험 결과
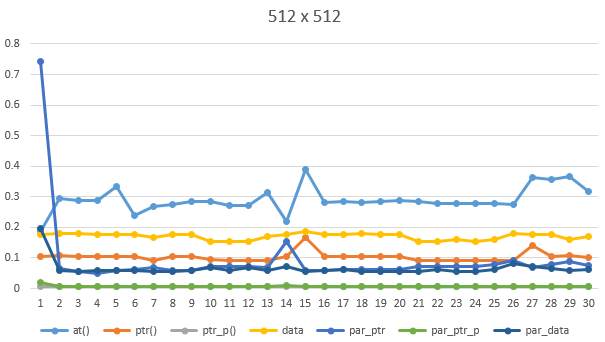
512 x 512 영상
1024 x 1024 영상

2048 x 2048 영상

4096 x 4096 영상

8192 x 8192 영상

16384 x 16384 영상
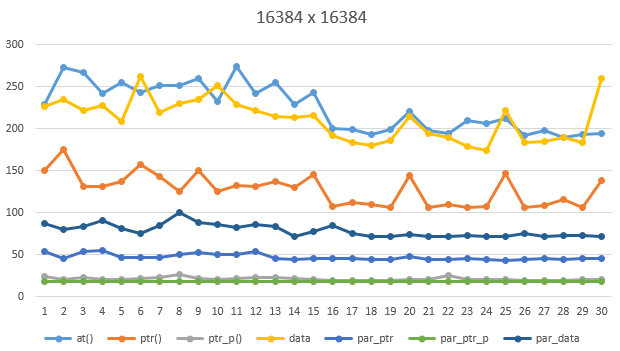
일단 그래프 분석부터 해 볼께요.
일반적으로, at은 느리고, data와 ptr은 빠르다고 알고 있습니다. 하지만 제 측정 결과는 다르네요.
1. at 사용 분석
at은 디버그 모드에서는 위치 유효성 검사를 하기 때문에 data나 ptr에 비해 매우 느립니다.
하지만 release 모드에서는 최적화(예외처리 안함)가 되어 data와 유사한 속도를 나타내고 있습니다.
예외처리 때문에 at을 사용하시는 분들은 release 모드에서는 제대로 동작 안할 수 있으니 주의하세요.
at은 영상 사이즈가 커질수록 속도가 급격히 늘어나네요.
2. ptr 사용 분석
ptr은 메모리 직접 접근하여 원소 정보에 접근하는 방법으로 속도가 빠릅니다.
순차탐색이 아닐 경우에는 약간 복잡해지겠지만 일반적으로 전체 영상을 순차탐색 하는 경우가 많으므로
ptr에 익숙해지시면 좋을 것 같습니다.
2.1 ptr 속도 최적화 분석
2번과의 차이가 느껴지시나요? pSrc[x] 로 접근하는 것과, 포인터 주소를 직접 ++ 하는 방법이 다르죠.
아무래도 pSrc[x]로 접근을 하면 변수가 추가되기 때문에 cpu 클럭이 더 필요하게 됩니다.
변수를 계속 ++ 해줘야 하는 것도 포함해서요. 그러나 포인터 주소를 직접 ++ 해주면
변수 관리에 의한 overload가 없어지기 때문에 빨라집니다.
하지만 이는 순차 탐색일 경우에만 적용된다고 생각하시면 됩니다.
3. data 사용 분석
일반적으로 data는 ptr과 속도가 유사하다고 설명을 합니다.
물론 작은 영상에서는 0.1ms 차이도 안날만큼 미미한 차이이지만 사이즈가 커지면서 data도 한계가 있습니다.
이유는 변수 관리 때문이죠. 내가 원하는 위치를 계산하기 위해 곱셈과 덧셈, 변수가 관리되어야 하기 때문입니다.
하지만 내가 원하는 위치를 바로 접근할 수 있는 장점이 있습니다.
그런 경우에 사용하세요.
4. parallel_for 이용한 ptr 사용 분석
병렬 처리를 위해 parallel_for를 사용하는 경우가 많이 있습니다.
512x512 영상 그래프에서 보면, 처음 1회 속도가 현저히 느린 것을 볼 수 있습니다. 이는 쓰레드 생성/할당 등에 시간이 소요가 되어 그렇습니다. 하지만 일단 생성 및 할당이 되면 제 속도가 나오죠. 예제는 단순한 계산만 있었지만,
복잡한 연산들이 들어갈 경우, 그리고 영상 사이즈가 클 경우에는 병렬 처리가 효과가 있죠.
4.1 parallel_for 이용한 ptr 최적화 속도 분석
2.1 결과와 비교해보면, parallel_for에 대한 효과가 적죠? 최신 컴파일러가 알아서 최적화를 해 주기 때문에
그런 것 같습니다. 하지만 영상이 커지거나 복잡한 연산이 수행될 때에는 약간의 효과를 볼 수 있으니 알아 두세요.
더 큰 영상을 처리할 때에는 좀 더 차이가 날 수 있습니다.
5. parallel_for 이용한 data 사용 분석
그냥 data 만을 사용한 것보다는 속도가 빠릅니다. 사실 data 쪽은 속도 최적화를 하지 않았기 때문에
속도 최적화 하지 않을 경우에는 parallel_for가 효과가 있다는 것이 증명되었죠?
data를 자주 쓰시는 분들은 속도 최적화를 한번 시도해 보세요.
결론을 내기 전에,
방법별로 영상 사이즈가 커짐에 따라 속도 변화량을 확인해보면, 아래와 같습니다.

여기에서 1,2 등은 역시 ptr 속도 최적화 버전이니까.
이 것들만 좀 더 확인해 볼께요. 범위를 좀 줄여봤는데, parallel_for을 사용하는 것이 약간 우세하게 나왔습니다.
영상이 커지면 병렬처리의 효과가 아주 약간 보입니다.

하지만 우리는 보통 2048x2048 이하의 영상을 다룰테고, 둘의 차이는 ms 이내이기 때문에 병렬처리를 꼭 할 필요는 없어 보이네요.
실험 고찰
1. ptr을 사용하는 것을 권장함
2. for 문 등 변수 없는 것을 사용할 경우 속도가 빨라진다. 즉, 평소 프로그래밍을 할 때에도 range for 등을 활용하면 좋겠다.
3. 병렬 처리는 속도 최적화를 진행하면 별 효과가 없으나 ROI 설정 등이 되어 일부 영역(연속되지 않은 메모리 접근)만 접근할 경우 parallel_for + data도 고려해보자.
4. 병렬 처리 처음 수행할 때에는 쓰레드 생성/할당에 시간이 소요될 수 있다. (물론 적은 시간이지만 빠른 연산의 경우에는 느껴질 수 있음)



