우리가 파이썬에서 데이터를 읽어 올 때 에러가 나는 경우를 종종 볼 수 있습니다.
아래와 같이 판다스의 read_csv() 함수로 csv 파일을 읽어왔는데, 에러가 뜹니다.
에러의 제일 아래쪽을 보니,
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x85 in position 3375: invalid start byte 라는 메시지가 보이네요.

원인은 read_csv() 함수가 기본적으로 encoding이 utf-8로 세팅 되어 있는데, 파일이 utf-8로 읽을 수 없다는 내용입니다.
구글링을 해 보면 많은 분들이 'cp949' 로 바꿔보면 된다 라고 하십니다.
그래서 저도 한번 encoding을 'cp949'로 바꿔봤습니다.

그래도 여전히 유사한 에러가 나옵니다.
UnicodeDecodeError: 'cp949' codec can't decode byte 0x80 in position 24483: illegal multibyte sequence

아 이거 어쩌지?
해당 파일을 notepad++ 로 열어보니 아래와 같이 인코딩이 ANSI로 되어 있네요.

그럴 땐 encoding = 'ANSI' 를 넣어주시면 해결됩니다.

이제 에러가 없네요.
그럼 데이터를 잘 읽어 왔는지 한번 확인해볼께요.
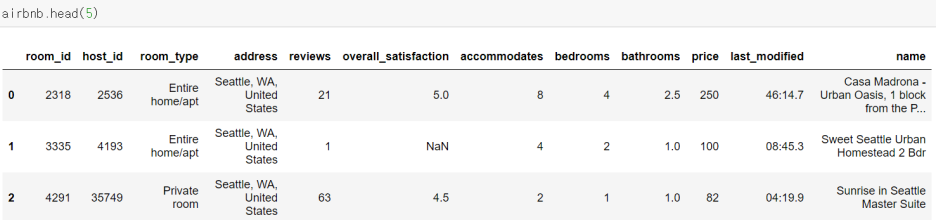
잘 읽어 옵니다.
이제부터는 read_csv()로 데이터 읽기에서 에러가 난다. 싶으면,
notepad++로 그 파일을 읽어 보고 어떤 형식으로 인코딩이 된 데이터인지 확인하는 거 잊지 마세요.
그럼 다른 파일도 확인해볼께요.

이건 UTF-8로 인코딩 되어 있는 파일입니다.
아래와 같이 EUC-KR 로 인코딩 되어 있는 파일은 'cp949'로 디코딩하여 읽어 주시면 됩니다.
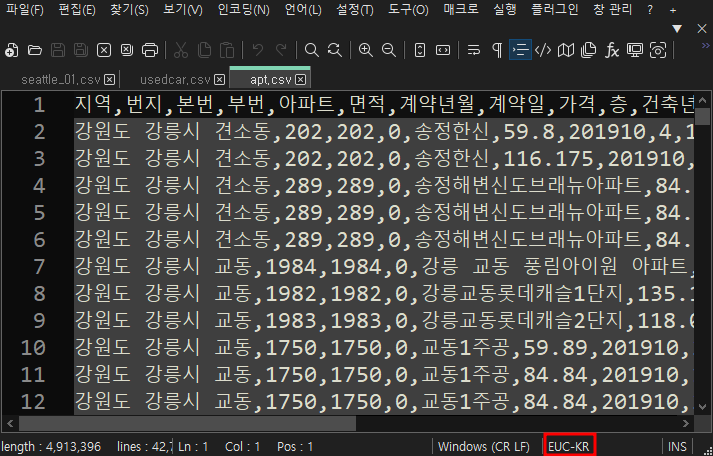

보통 한글 인코딩 유형에는 'cp949', 'utf-8', 'euc-kr'이 대표적입니다.
왜 데이터를 저장하거나 전송할 때 인코딩을 할까요?
데이터 크기를 줄여서 최대한 빠르게 저장할 수 있게 하려 함입니다.
인코딩 종류
(1) 유니코드 (Unicode)
유니코드는 전세계 모든 글자를 하나의 코드표로 표현하였기 때문에 가장 범용적인 코드표입니다. 많이 사용하는 방식 중 하나인 UTF(Unicode Transformation Format)은 유니코드표를 사용한 인코딩 방식입니다.
윈도우와 자바에서는 UTF-16을 사용하고 나머지는 거의 UTF-8을 사용합니다.
(2) ASCII(Americal Standard Code for Information Interchange)
프로그래밍을 좀 해봤으면 가장 많이 들어봤던 아스키 코드표, 이걸 말하는 아스키 입니다. 미국에서 정의한 표준화 부호체계로 128개의 고유값을 사용합니다.
(3) ANSI
ASCII의 7비트로 다양한 언어를 할당하기에는 부족해서 8bit로 확장한 것이 바로 ANSI. ANSI는 256개의 문자를 표현할 수 있습니다.
인코딩 방식 중 euc-kr, cp949가 한글에 대응되는 CodePage 입니다.
한글을 인코딩 하기 위해서는 보통 cp949, utf-8, euc-kr을 사용하는데, utf-8을 사용하면 유니코드표에 매핑이 되고, cp949를 선택하면 ansi CodePage에 매핑이 됩니다.
메모장에서 ANSI를 선택하면 cp949로 인코딩 됩니다.
인코딩과 디코딩의 뜻은 정확히 뭔가요?
인코딩은 문자 → 바이트로 변환하고,
디코딩은 바이트 → 문자로 변환하는 것 입니다.
즉 인간과 컴퓨터가 소통하기 위한 수단으로써 인코딩/디코딩을 하는 것 입니다.
즉, 한국 사람은 한글을 알아들으니 한글을 보여주고, 컴퓨터는 한글을 모르고 0, 1로만 소통하니까 바이트 코드를 보내주는 것이죠.
아스키 코드가 가장 초창기에 사용된 코드 입니다. 아스키 코드는 7bit 또는 8bit를 사용해서 영어 알파벳과 기호, 각종 제어 문자를 사용하던 코드입니다.
영어 알파벳은 대문자 26개, 소문자 26개를 합해도 52개밖에 되지 않습니다. 그래서 128(7bit)로도 충분했던 것이죠. 하지만 한글은 3성(초성,중성,종성)을 다 합하면 11,172개의 조합이 나옵니다. 1byte의 컴퓨터 메모리에는 256개까지 표현할 수 있으니 한국, 중국, 일본 같은 나라(한자가 포함되어 많음)는 2byte의 조합이 필요한 것이죠. 16 bit는 65,536개를 표현할 수 있기 때문이죠.
그럼 인코딩 방식에 대해 좀 더 설명을 해볼께요.
- UTF-8
한글자를 8bit로 표현하는 인코딩 방식이고 한 문자를 표현할 때 1-4바이트의 가변 길이 인코딩 방식(Variable-width encoding) 입니다. 가변 길이 방식을 사용하여 효율적이고 가장 널리 쓰이는 인코딩 방식입니다.
- EUC-KR
아스키와 ANSI는 각 7비트, 8비트로 한 문자를 표현하는데 한글은 2바이트로 표현해야 하며, 이렇게 표현하는 인코딩 방식을 euc-kr이라고 합니다.
- CP949
EUC-KR의 superset(확장)이며 euc-kr에서 표현할 수 없는 한글도 표현할 수 있습니다. 따라서 cp949를 euc-kr로 인코딩을 할 수 있지만 euc-kr을 cp949로 인코딩 하는 것은 안됩니다.



