지난번 까지는 파이썬의 기본 문법들에 대해 알아봤습니다.
이번부터는 좀 더 본격적으로 파이썬 라이브러리들에 대해 알아보겠습니다.
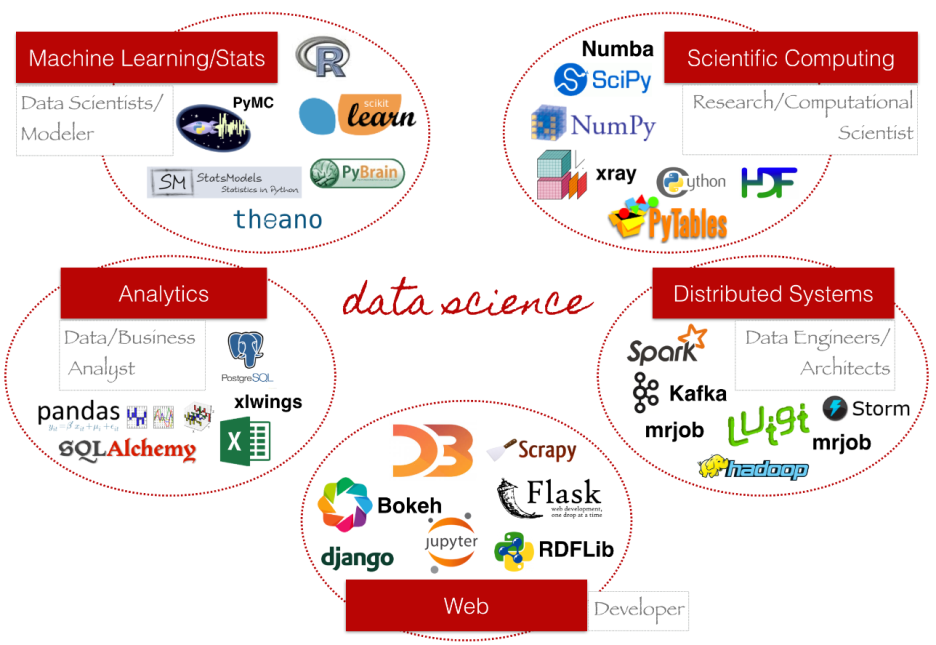
지난번에 데이터 분석에 대한 개요를 알아보면서 데이터 분석 단계를 한번 정리해드렸습니다. 이번에는 데이터 분석 단계별 사용가능한 파이썬 패키지에 대해 알아볼까 합니다.
[데이터 분석][Python] Data Science 란? 파이썬 사용 이유 데이터 사이언스 Scientist 사이언티스트 아나
지난 시간에 데이터 분석 첫시간으로 아나콘다를 설치하는 방법과 쥬피터 노트북에 대한 간단한 실행에 대...
blog.naver.com

이번에는 넘파이에 대해 알아보겠습니다.
넘파이는 수치 해석용 파이썬 패키지 입니다. 즉, 숫자형밖에 사용할 수 없습니다.
2008년에 Pandas 패키지가 나오고 난 후에 Pandas가 기본적으로 넘파이 기반으로 만들어졌기 때문에 Numpy의 대부분의 기능이 포함되어 있습니다 그래서 Pandas 패키지를 많이 사용하고, 최근에는 Numpy를 딱 두가지 용도로만 사용합니다.
1. 배열 사용 시 (다차원 배열 사용 가능)
2. 난수 생성 시

아나콘다를 설치하셨다면 Numpy 패키지는 기본으로 설치가 되어 있습니다.
주피터 노트북에서 패키지를 깔아야 할 때에는 앞에 ! 를 쓰고 pip install 을 사용하시면 됩니다.

그런데 저는 numpy가 설치되어 있어서 위와 같은 메시지가 나왔습니다.
numpy 맛보기
Numpy를 사용하기 위해서는 먼저 import를 해야 합니다.
패키지를 import 할 때에는 보통 아래와 같은 규칙으로 하면 됩니다.
'numpy 패키지를 import 할껀데 다음부터는 np라고 명칭을 써서 사용할꺼야' 란 뜻 입니다.

(1) 배열 만들기
넘파이의 array 함수에 리스트를 넣으면 ndarray 클래스 객체, 즉 배열로 변환해 줍니다.
list를 만들고 np.array()에 list를 넣으면 type이 numpy.ndarray 형이라는 것을 보여줍니다. 리스트와 numpy의 배열과 다른 점은 C언어의 배열처럼 연속적인 메모리 배치를 가지기 때문에 모든 원소가 같은 자료형이어야 합니다. 대신 원소 접근과 반복문 실행이 빠릅니다.

아래와 같은 예시를 살펴보겠습니다.
아래 원소에 각각 2배씩하는 경우 list인 경우 for문을 이용하여 아래와 같이 계산을 해야 하는데, numpy 배열의 경우 바로 객체에 바로 2를 곱하면 됩니다.

참고로 list에 그냥 2를 곱하면 아래와 같이 list의 크기가 2배가 됩니다.

Numpy에서 가장 많이 사용되는 것은 바로 다차원 배열입니다.
2차원 배열을 행렬(matrix)라고도 합니다.

아래와 같이 명령어를 두개 이상 붙일 수 있는데, 이것을 명령어 chain 이라고 합니다.


Numpy는 행렬 연산에 강하다고 했습니다.
예를 들어 2x3 행렬을 만든 다음에 전치행렬을 만들어 보려면 아래와 같이 하면 됩니다. (두가지 방법 모두 가능합니다.)

Numpy는 아래와 같은 연산들이 가능합니다.


Numpy에서 아래와 같이 기초 통계를 위한 연산이 가능합니다.
하지만 나중에는 Pandas를 더 많이 사용하게 될꺼에요.

(2) 난수 생성
난수 생성은 Numpy의 random 패키지에서 제공을 합니다. 따라서 np.random 을 사용해야 합니다.
난수는 엄격한 의미에서는 무작위 수가 아닙니다. 어떤 특정한 시작 숫자를 정해 주면 컴퓨터는 정해진 알고리즘에 의해 수열을 생성하는 것 입니다. 이런 시작 숫자를 seed라고 합니다. 시드를 숫자로 정해주면 나중에도 같은 난수를 생성해주기 때문에 문제 발생 시 재현하여 디버깅을 하는데 편리한 장점이 있습니다.
난수 생성에는 아래와 같이 3가지 함수가 있습니다.
- rand: 0~1 사이의 균일 분포 난수 생성
- randn: 표준 정규 분포에 맞는 난수 생성
- randint: 균일 분포의 정수 난수 생성

randint는 아래와 같은 함수 원형을 가집니다.
함수 원형(설명)을 보시려면 함수에 커서를 놓고 Shift + Tab 을 누르시면 아래와 같이 보실 수 있습니다.

randint(low, high-None, size-None, dtype=int) 라고 되어 있습니다.
high를 입력하지 않으면 0~low 사이의 숫자를,
high를 입력하면 low~high 사이의 숫자를 출력합니다.
size는 난수의 사이즈(행렬 가능)를 의미합니다.


데이터에서 일부를 무작위로 선택하는 것을 표본선택, 또는 샘플링이라고 합니다. 샘플링에는 choice 라는 메소드를 사용합니다.
numpy.random.choice(a, size=None, replace = True, p=None)
- a: 배열이면 원래의 데이터, 정수이면 arange(a) 명령으로 데이터 생성
- size: 정수, 샘플 숫자
- replace: True이면 한번 선택한 데이터 다시 선택 가능
- p: 배열로 입력, 각 데이터가 선택될 수 있는 확률




